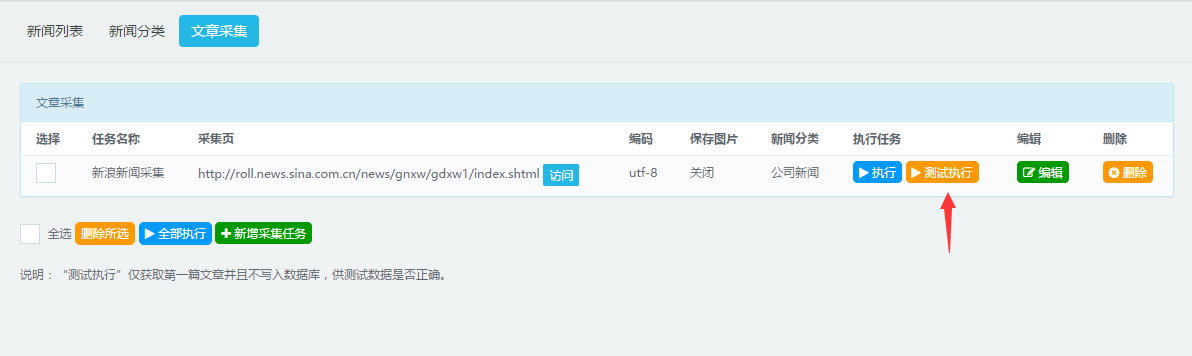
为减轻网站编辑人员的工作量,本套系统新增了文章采集功能,可以一键采集其他网站的文章,同时支持将图片保存在本地服务器。
接下来介绍如何使用采集功能
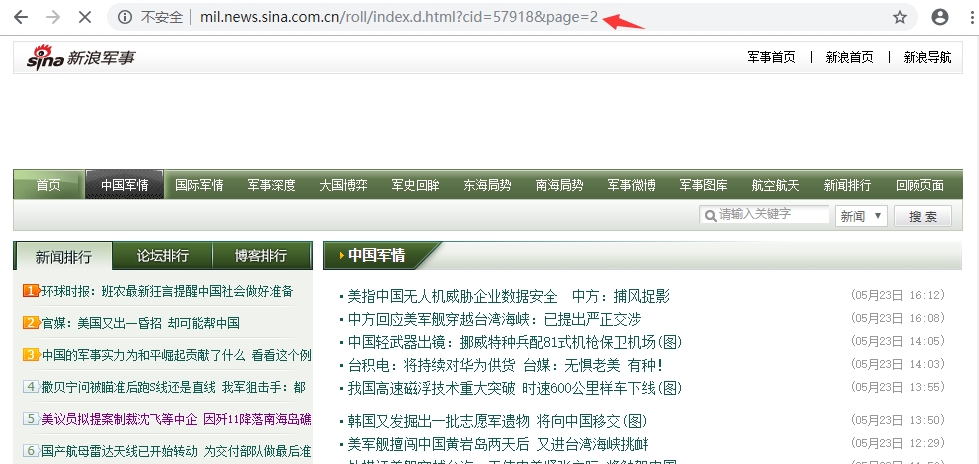
1.找到一个其他网站的文章列表页,作为采集源头 比如 http://mil.news.sina.com.cn/roll/index.d.html?cid=57918&page=1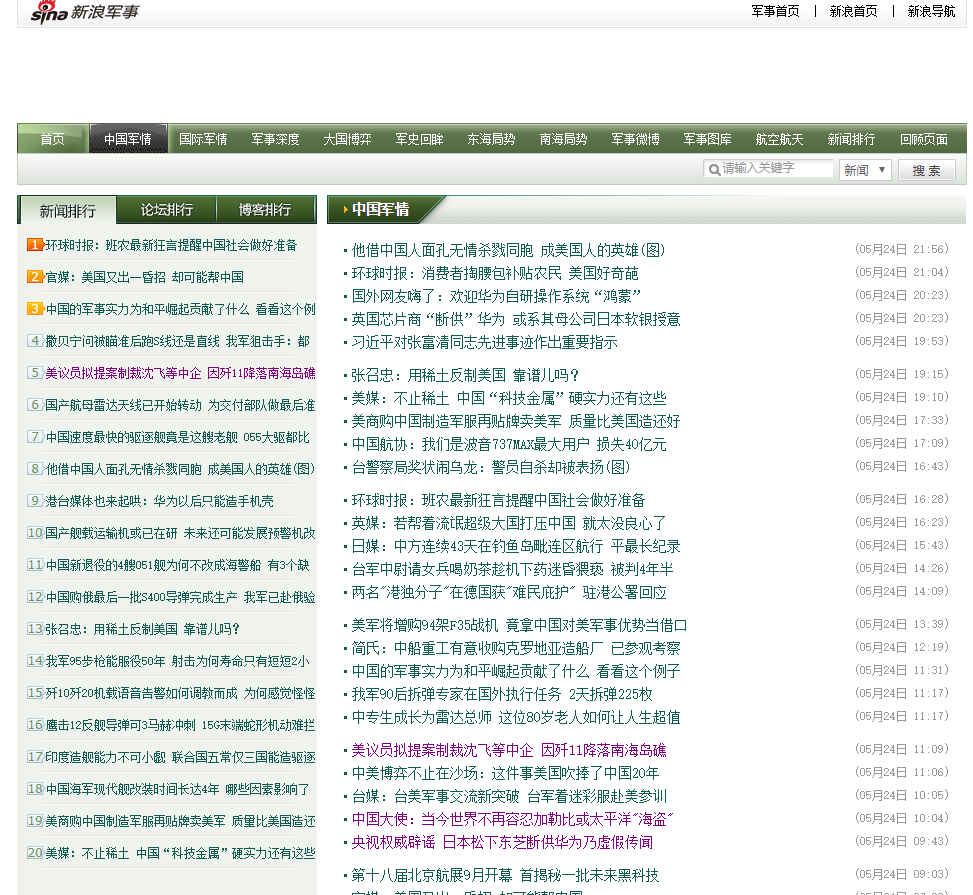
2.获取列表页的采集区域 (推荐使用谷歌浏览器,右键-查看源代码)
开始标记和结束标记在每个页面都不一样,需根据自己的实际情况来填写
说明:开始标记和结束标记必须为页面中唯一或者第一次出现
3.如果新闻列表页有分页,还可以设置采集某几页,使用通配符{page}代表页数
比如 http://mil.news.sina.com.cn/roll/index.d.html?cid=57918&page={page}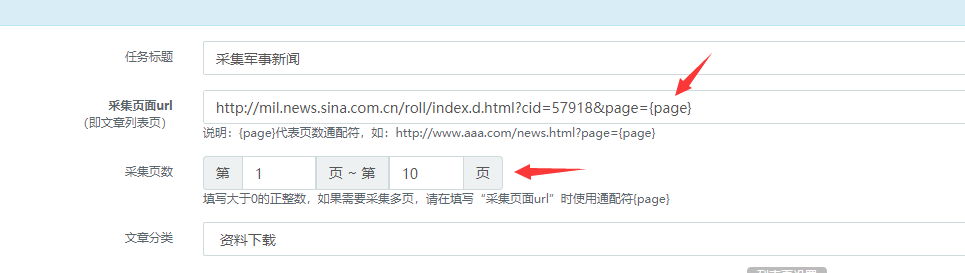
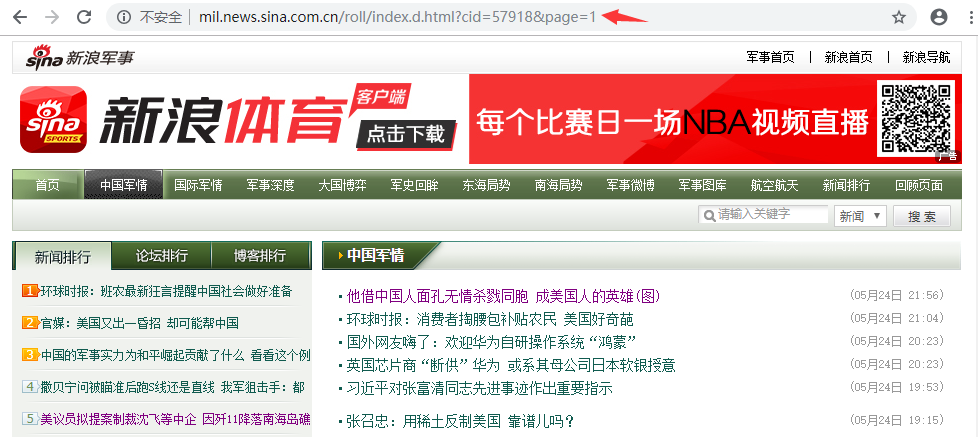
4.进入内容页,获取内容页的采集区域 (推荐使用谷歌浏览器,右键-查看源代码)

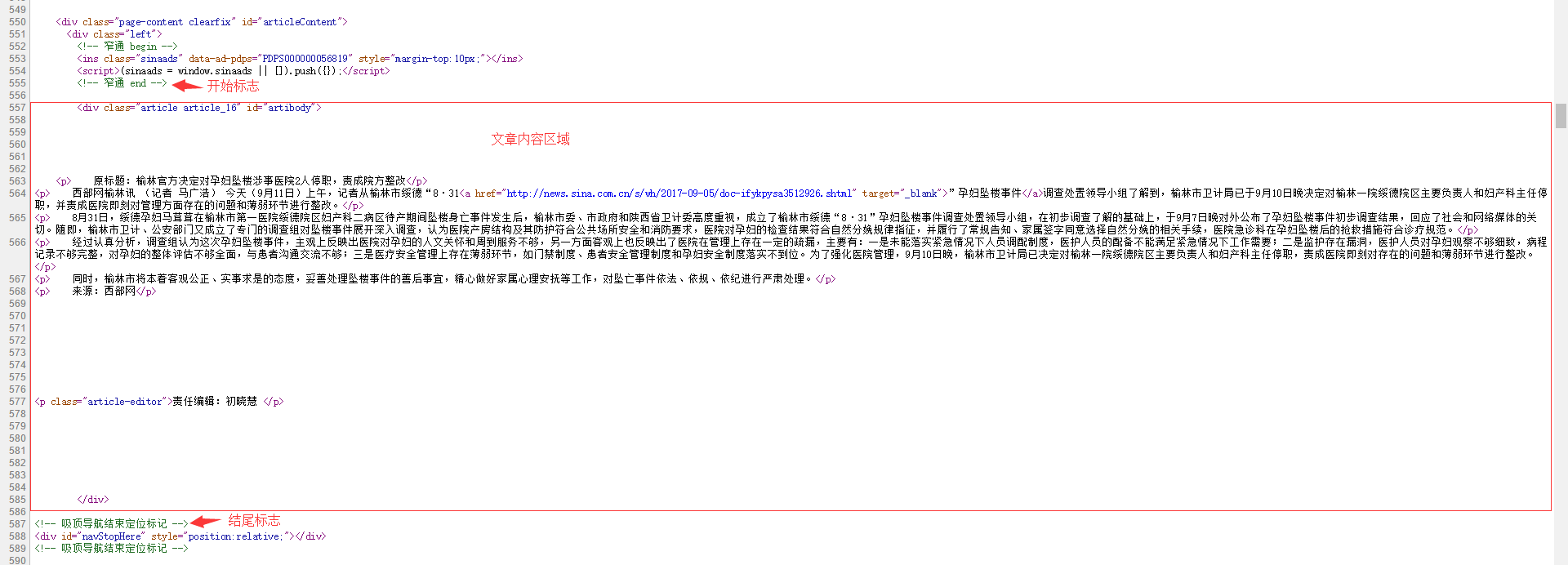
开始标记和结束标记在每个页面都不一样,需根据自己的实际情况来填写
说明:开始标记和结束标记必须为页面中唯一或者第一次出现
5.查看内容页编码(在中国,网页编码一般有gb2312和utf-8两种,可以从源代码顶端查看,一般都有标注)

6.采集任务设置完成后,可以先测试执行,如果能准确的获取到第一篇文章,那么就可以开始执行采集任务了。